We just moved our production web app off Next.js and onto a Vite SPA. 236K lines of code, paying enterprise customers, zero downtime. Six weeks, off and on, with a small team leaning hard on AI agents.
Here’s the technical version of how — and what we’d tell you if you’re staring down the same thing.
The key insight: don’t rewrite, re-route
The temptation with a framework migration is to rebuild everything. Don’t.
We had ~166K lines of React components. None of that code cares whether Next.js or Vite is mounting it. The framework is the shell — routing, data fetching, the build. The components are just components.
So we kept all 166K lines exactly where they were and pointed the new app at them with TypeScript path aliases. The “new” frontend is a ~16K-line routing shell built on TanStack Router. Each route file wraps the same component Next.js was wrapping.
Most route ports were under 30 lines. We changed the framework layer and touched almost none of the features.
Why we could even do this
Honest answer: we were paying for SSR we didn’t use.
Our app is a client-side SPA behind auth. We weren’t server-rendering anything meaningful — just eating the cost of it. Hydration mismatches. Server/client component boundaries. 5-minute builds. The “use client” confetti everywhere.
Once we admitted we didn’t need any of that, the whole thing got simple. If you’re genuinely using SSR/RSC/ISR, this playbook doesn’t apply to you. Be honest about which camp you’re in before you start.
The new stack
- Vite for the build and dev server. HMR went from “go get coffee” to instant.
- TanStack Router for type-safe, file-ish routing. The route tree is generated; the params are typed end to end.
- Hono on Bun for the backend — the API and anything that used to live in Next.js API routes / server actions.
- Path aliases (
@webapp-core/*,@webapp-spa/*,@webapp-api/*) so the three packages import each other explicitly. We later replaced the old@/and@core/aliases entirely so resolution is unambiguous — no more “does this resolve to my package or the shared one?”
We split the monorepo into core/ (shared), apps/api/ (Hono), and apps/spa/ (Vite). Clean package boundaries made the agent work parallelize cleanly too.
We ran this on agents
The route ports were mechanical and repetitive — perfect for AI agents.
We’d fire off 5-6 Claude Code agents at once, each in its own git worktree, each porting a different route. A batch that’d take a human half a day landed in ~20 minutes.
What worked:
- Agents are great at pattern-following work — route ports, config files, mechanical refactors, addressing review feedback.
- Fresh-context self-review beats author review. We never let the agent that wrote the code review it. Author bias is real, even for an LLM. A zero-context reviewer cross-referencing the actual codebase caught bugs the author missed.
- Verify agent claims against the diff. Agents will confidently describe files and changes that aren’t in the PR. We learned to grep the diff before trusting a review. (One agent invented a 1,200-line feature that didn’t exist. Fun day.)
What still needed humans: architecture calls, subtle auth debugging, and the “is this actually safe to ship” judgment. The agents even found a real auth bug in our admin path that QA missed — but a human had to recognize why it mattered.
Shipping it without anyone noticing
We never did a big-bang cutover. We ran V2 on a separate subdomain for weeks, in parallel with V1.
The actual switch was a single Kubernetes HTTPRoute change — point app.endgame.io at the new webapp-api-srv + webapp-spa-srv, turn the old subdomain into a 301 redirect. That’s it. The scariest moment of the whole project was editing one YAML file, because everything behind it was already battle-tested.
Before we flipped traffic, we made sure the boring production stuff was done:
- Graceful shutdown —
server.stop(false), preStop hooks, health checks that return 503 during drain so the load balancer stops routing before pods die. - Version skew detection — when we deploy a new SPA build, clients on the old build get told to reload instead of hitting a stale API contract.
- HPA, PDB, liveness probes — the unsexy reliability scaffolding. Do it before the traffic, not after the incident.
- A rollback we’d actually tested. Flipping the HTTPRoute back was one command, and we’d practiced it.
The payoff
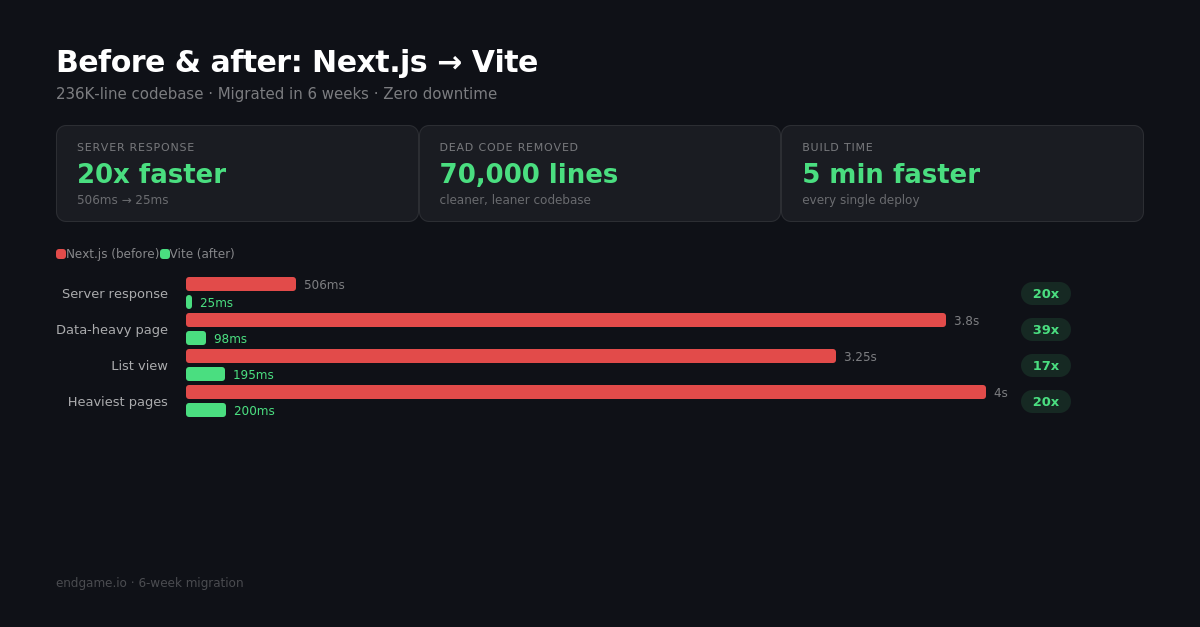
- Server response time dropped from ~506ms to ~25ms.
- The heaviest pages went from 3-4 second loads to under 200ms.
- We deleted ~70K lines of dead code on the way.
- Deploys got faster — killing the 5-minute Next.js build was most of it.
The mental model for users changed too. It used to be “is the app even working?” during a multi-second blank screen. Now the shell paints in ~25ms and data streams in. The question became “how fast does the data load,” which is a much nicer problem to have.
What we’d tell you
- Ask if you actually need your framework’s headline feature. We didn’t need SSR. That admission unlocked everything.
- Re-route, don’t rewrite. Path-alias your existing components into the new shell. The features don’t need to know.
- Use agents for the mechanical 80%, fresh-context review for safety, and humans for the judgment calls.
- Run both versions in parallel and make the cutover a one-line, reversible config change.
- Do the production hardening before the traffic, not after.
Six weeks. No feature rewrites. No downtime. One nervous YAML edit.