“Prompt caching saves money” is one of those things everyone repeats and almost nobody quantifies. The vendor docs wave at it. Blog posts wave at it. We were waving at it too — right up until someone asked the obvious question in a meeting: okay, how much?
We didn’t know. So we went and found out. Here’s the real number, measured against our own bills, and the small pile of engineering that earns it.
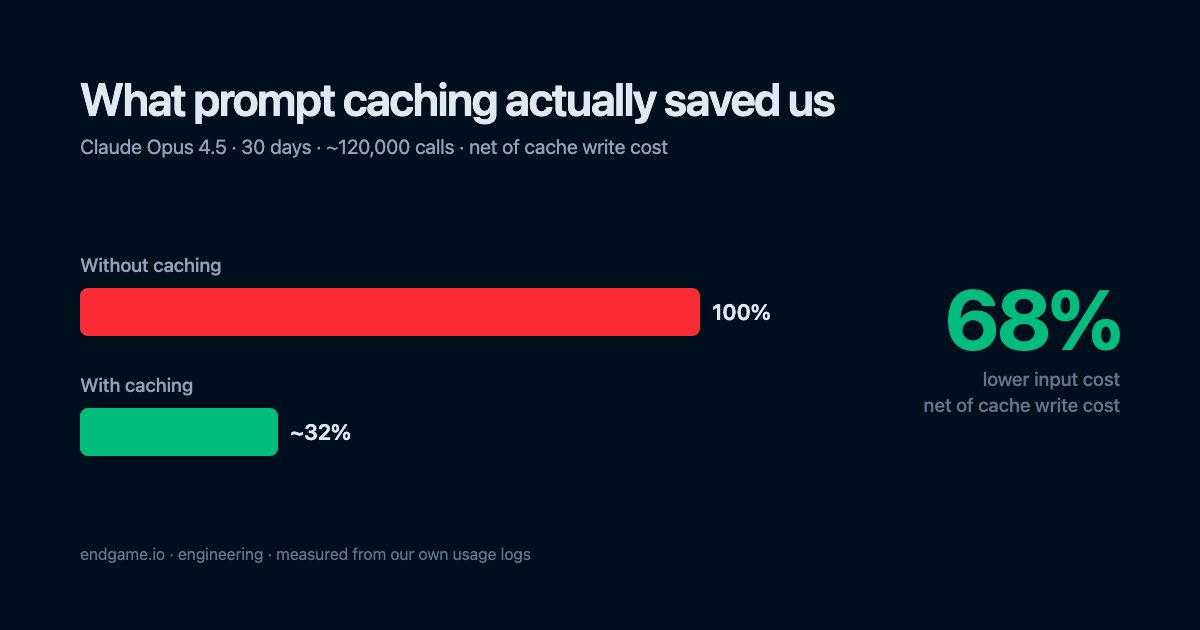
On Claude Opus 4.5 — our most-used model — prompt caching cut our input-token cost by about 68% last month. And that’s the net number, after subtracting what the cache costs to run.
Let’s unpack that, because the “after subtracting” part is where most savings claims quietly cheat.
What prompt caching even is
When you call an LLM, you pay per token of input. If you send the same big chunk of text on every request — a long system prompt, a fixed set of instructions, a schema — you’re paying full freight to re-process identical bytes over and over.
Prompt caching lets the provider keep that stable prefix “warm.” The first time, you pay a little extra to write it into the cache. Every time after, the cached part is billed at a deep discount — on Anthropic, cache reads run about 10% of the normal input price.
So the deal is: pay a small premium up front, then pay a tenth of the price on every repeat. It’s a fantastic deal if your prompts have a big, stable, reused front. Which brings us to the catch.
The catch: caching only works if you’re disciplined about your prompts
A cache hit requires a byte-for-byte identical prefix. Not “basically the same.” Identical. Change one character near the front of your prompt and the whole thing is a miss — you pay the write premium again and get none of the discount.
That sounds easy until you remember how prompts usually get built: f-strings stuffing the user’s name and the current timestamp and today’s data right into the middle of the instructions. Every request is a unique snowflake, and the cache never hits.
The fix is a layout discipline, not a feature. You put everything stable at the front, everything variable at the back, and you draw a hard line between them:
# The long, stable system prompt lives at the front and carries a
# cache breakpoint. Any byte change here invalidates the cache for the
# whole run — so it must NOT contain per-request data.
messages = [
{
"role": "system",
"content": SYSTEM_PROMPT, # big, fixed, reused every call
"cache_control": {"type": "ephemeral"},
},
{
"role": "user",
"content": todays_data, # all the variable stuff goes here
},
]That cache_control: ephemeral is the breakpoint: “cache everything up to here.” The rule we hold ourselves to is simple and unforgiving — nothing that changes per request is allowed in front of the breakpoint. No names, no timestamps, no row data. Those go in the user message, after the line. Get that right and the front of every request is identical, so it hits the cache every time.
One of our heaviest workloads is a great fit for this: an analysis renderer with a giant, fixed system prompt — pages of instructions on how to write the report — followed by a small slug of fresh data per run. Big stable front, tiny variable back. Exactly the shape caching loves.
Now, the honest accounting
Here’s where we refused to flatter ourselves. Plenty of “we saved 90%!” claims only count the discount on cache reads and conveniently forget that you pay extra to write the cache in the first place. That write premium is real — on Anthropic it’s about 125% of the normal input price. If you ignore it, your savings look better than they are.
So we pulled 30 days of actual usage for Claude Opus 4.5 — every call, straight from our LLM gateway’s billing records. To keep the math clean (and our finance team calm), here’s everything as a share of one baseline: what those same requests would have cost with caching turned off = 100. Against that, here’s what we actually paid:
| What we paid for | Share of the no-caching cost |
|---|---|
| Genuinely new input tokens | ~2% |
| Tokens served from cache (the ~10% rate) | ~10% |
| Writing things into cache (the ~125% premium) | ~20% |
| Total input-side cost, with caching | ~32% |
Read that bottom row again: we paid about 32% of what we’d have paid with caching off. Which means:
| Share of no-caching cost | |
|---|---|
| Without caching | 100% |
| With caching | ~32% |
| Net savings | ~68% |
Sixty-eight percent. After paying the full write premium. On about 120,000 calls in a month.
And if you want the number for the bytes caching actually touches: the tokens we served from cache would have been ~90% of the no-caching cost at full price, and we paid about a tenth of that for them. That’s a 90% discount on the cached portion. The 68% is the all-in figure once you’ve honestly subtracted the cost of running the cache; the 90% is what the discount does to the bytes it hits. We lead with 68% because it’s the one that survives scrutiny.
Why we could just… answer the question
The reason we could produce this in an afternoon instead of a forensic project is that every LLM call in our system goes through one gateway, and the gateway writes down the token and cost breakdown for every request — input, output, cache reads, and cache writes split out by 5-minute and 1-hour cache lifetimes. “How much does prompt caching save us on Opus” went from a shrug to a single SQL query over our own logs.
That’s the quiet lesson here, more than the 68%. Anyone can turn on prompt caching. The thing worth building is the ability to prove what your infrastructure is doing — so the next time someone asks “okay, how much?”, the answer is a number, not a vibe.
The takeaways
- Caching pays, but only if your prompts are built for it. Stable stuff in front, variable stuff behind a breakpoint, and a hard rule that per-request data never crosses the line.
- Count the write premium. Savings claims that only count cache-read discounts are fibbing. Ours is net of the ~125% write cost, and it’s still 68%.
- Instrument first, optimize second. We didn’t estimate the savings — we measured them, because the plumbing was already capturing per-request cost. Build the scoreboard before you start keeping score.
A two-thirds cut, on one model, for a layout discipline and a single cache_control line. We’ll take it.